
Just four months into the year, we’re seeing a massive shift in memory availability and costs, CPU prices, and so on. Here, we dive deeper into the memory and overall infrastructure cost, and how the modern CIO can tackle Infrastructure Economics in the AI Era.
Over roughly the last two decades, “cost optimization” in infrastructure mostly meant buying in bulk and squeezing better discounts out of vendors. That playbook no longer succeeds in the AI era. The economics of private cloud are now dominated by three forces: how you tier memory and storage, how you handle data reduction, and how you efficiently turn power and cooling into useful work for CPUs and GPUs.
In a world of dense accelerators and rapidly rising energy demands, standing still by refreshing like‑for‑like hardware or overprovisioning “just to be safe” can often be the most expensive options you can choose.
Instead of focusing primarily on unit prices and discounts, an emphasis on design choices changes the slope of the cost curve. For example, using NVMe tiering to buy less premium memory, using deduplication and compression to buy and power less raw storage, and redesigning around power and cooling limits so each rack delivers more work per watt and more useful GPU hours.
The CIO Playbook for the New Economics of Private Cloud
When an executive thinks about a proactive infrastructure economics strategy, they should treat infrastructure less as a sunk cost and more as a series of tunables that you can use over time. The goal is to keep lowering the cost of a unit of business value (a VM, a TiB, a GPU hour, a transaction) while staying within power, cooling, and risk constraints.
- Start with Cost Per Outcome, Not the Hardware Spend
Start by asking for simple metrics like cost per VM, per TB, per GPU hour, or per transaction, and track how they move quarter by quarter. Decisions about architecture, refresh cycles, and new features should be justified in terms of improving these unit costs, not just reducing line-item CAPEX.
- Drive Teams to Leverage Efficiency Features By Default
Treat capabilities such as NVMe memory tiering, deduplication, compression, and power-aware scheduling as standard parts of your deployment and a necessary part of a modern private cloud architecture. The standing question should be: “If we’ve turned this off, what is the clear business reason for paying more to deliver the same service?”
- Design Around Power and Cooling as Hard Constraints
Require every capacity plan to show not only how many servers or GPUs you can add, but how close you are to power and cooling limits at each site. Make “work per watt” and “work per rack” core design metrics so that new investments prioritize architectures that push those curves in the right direction.
- Institutionalize Continuous and Proactive Rightsizing
Expect regular reviews of idle resources, oversized instances, and underutilized clusters, with clear actions to reclaim or repurpose capacity. Make it normal for templates, reservations, and tiering policies to be adjusted based on actual utilization data, not one-time planning assumptions.
- Infrastructure as a Shared Resource
Represent core resources such as compute, memory, storage, GPU, and network as simple internal “tokens” with transparent prices, and give product teams budgets in those tokens. Combined with showback or chargeback, this lets teams see and manage their own infra consumption as a trade-off against feature work and reliability, instead of treating infrastructure as an invisible, fixed cost.
From Strategy to Specifics - Making the Potential Savings Tangible
The CIO playbook sets the direction — but strategy only lands when it's backed by concrete mechanics. So let's look at one of the most impactful levers available to infrastructure teams today: NVMe memory tiering. Understanding how it works makes the economics tangible, and the economics are where the real case gets made.
The Math Behind The Impact of NVMe Tiering
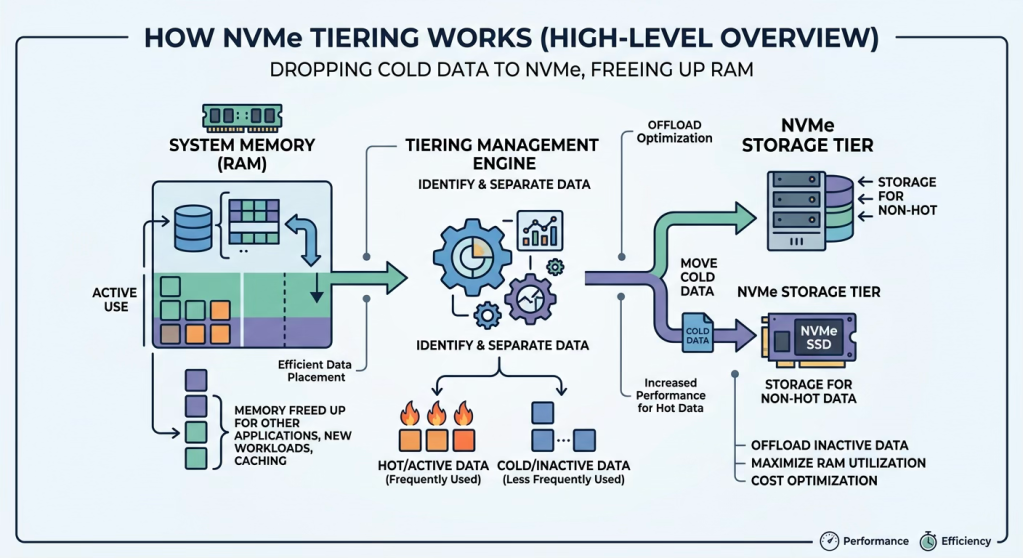
Let’s get into the weeds for a moment. NVMe memory tiering is a powerful tool because it’s hardware agnostic. It democratizes the use of hardware and it simply responds to how the application runs. The goal is to give every workload enough capacity without paying top‑tier prices for all of it. NVMe‑based memory tiering does this by presenting a single logical pool that is physically split into two tiers: a smaller DRAM (expensive) tier for the actively used working set, and a much larger NVMe, cheaper tier for less frequently accessed data.
By continuously tracking which application pages loaded in memory are “hot” and which are “cold,” the platform keeps only performance‑critical data in DRAM and offloads the rest to lower‑cost NVMe, so applications behave as if they have ample memory while you materially reduce how much premium DRAM you need to buy.
In practical deployments, this allows you to replace a large portion of DRAM with NVMe without starving workloads of memory. NVMe tiering can cut per-server memory cost on the order of 30–40% in many cases (Source: Broadcom Internal Testing), while maintaining or even increasing VM density because the total addressable memory grows.
Many environments can see as much as 50–65% reductions in memory spend because a significant fraction of provisioned memory is allocated but rarely touched; that “cold” portion is precisely what tiering can move off expensive DRAM. The net result is straightforward: slightly more complexity in the platform, in exchange for materially lower cost per VM and better utilization of the CPU you already own.
Strategically, it means you treat high‑performance media such as DRAM and NVMe as a relatively thin acceleration layer in front of a more capacious, cost‑efficient infrastructure resource pool, and you let the platform decide where data lives at any moment to balance performance and cost.
Adding Compression and Deduplication For Additional Savings
On the storage side, data reduction—deduplication and compression—is now one of the most effective levers for lowering the cost of private cloud capacity. Deduplication identifies identical blocks across virtual machines and keeps only one physical copy, while maintaining logical references so each VM still believes it has its own full dataset.
Compression then takes each unique block and encodes it more efficiently, shrinking the physical footprint further before data lands on the capacity tier.
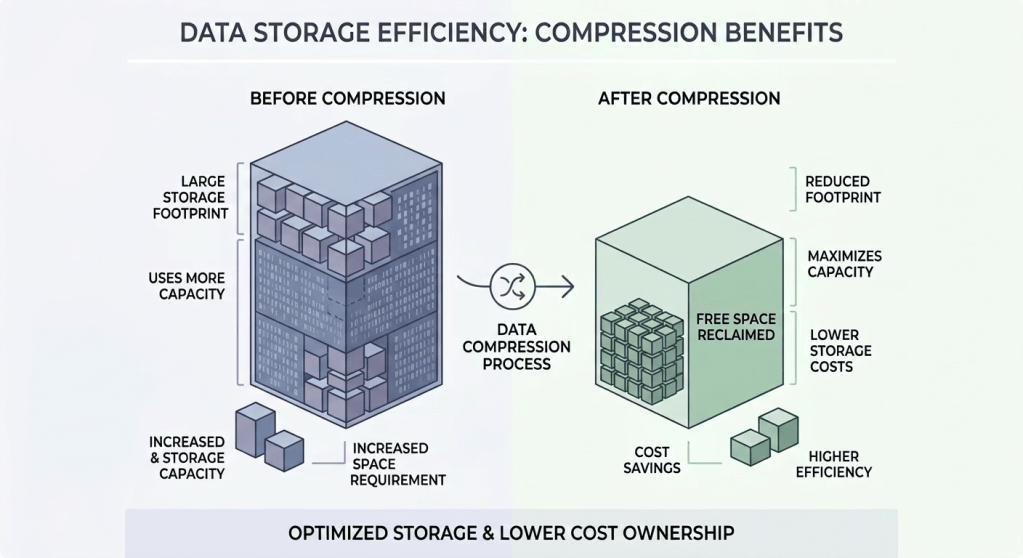
Because many enterprise workloads share large portions of their data, these techniques can significantly reduce the raw capacity you need to buy and power. In observed environments, enabling storage deduplication and compression has delivered effective savings in the mid‑teens to high‑twenties percent on cost per usable terabyte, and modeled comparisons show up to roughly one‑third lower total cost of ownership versus similar storage without these features.
Conclusion
The new infrastructure economics of private cloud are not about chasing the latest hardware trend; they are about treating memory, storage, power, and cooling as controllable variables in the cost of every infrastructure architecture you adopt and deploy.
Executives who succeed here do three things consistently: they insist on cost‑per‑outcome as the primary metric, they push their teams to use tiering and data‑reduction capabilities by default, and they make power, cooling, and capacity trade‑offs visible to the people who own applications and roadmaps.
If you can do that, infrastructure stops being a black box and becomes a tool you can use to fund new bets: paying for growth not by cutting corners, but by systematically lowering the cost of every VM, TB, and GPU hour you run